Thanks for using Compiler Explorer
Sponsors
Jakt
C++
Ada
Algol68
Analysis
Android Java
Android Kotlin
Assembly
C
C3
Carbon
C with Coccinelle
C++ with Coccinelle
C++ (Circle)
CIRCT
Clean
CMake
CMakeScript
COBOL
C++ for OpenCL
MLIR
Cppx
Cppx-Blue
Cppx-Gold
Cpp2-cppfront
Crystal
C#
CUDA C++
D
Dart
Elixir
Erlang
Fortran
F#
GLSL
Go
Haskell
HLSL
Hook
Hylo
IL
ispc
Java
Julia
Kotlin
LLVM IR
LLVM MIR
Modula-2
Mojo
Nim
Numba
Nix
Objective-C
Objective-C++
OCaml
Odin
OpenCL C
Pascal
Pony
PTX
Python
Racket
Raku
Ruby
Rust
Sail
Snowball
Scala
Slang
Solidity
Spice
SPIR-V
Swift
LLVM TableGen
Toit
Triton
TypeScript Native
V
Vala
Visual Basic
Vyper
WASM
Yul (Solidity IR)
Zig
Javascript
GIMPLE
Ygen
sway
rust source #1
Output
Compile to binary object
Link to binary
Execute the code
Intel asm syntax
Demangle identifiers
Verbose demangling
Filters
Unused labels
Library functions
Directives
Comments
Horizontal whitespace
Debug intrinsics
Compiler
mrustc (master)
rustc 1.0.0
rustc 1.1.0
rustc 1.10.0
rustc 1.11.0
rustc 1.12.0
rustc 1.13.0
rustc 1.14.0
rustc 1.15.1
rustc 1.16.0
rustc 1.17.0
rustc 1.18.0
rustc 1.19.0
rustc 1.2.0
rustc 1.20.0
rustc 1.21.0
rustc 1.22.0
rustc 1.23.0
rustc 1.24.0
rustc 1.25.0
rustc 1.26.0
rustc 1.27.0
rustc 1.27.1
rustc 1.28.0
rustc 1.29.0
rustc 1.3.0
rustc 1.30.0
rustc 1.31.0
rustc 1.32.0
rustc 1.33.0
rustc 1.34.0
rustc 1.35.0
rustc 1.36.0
rustc 1.37.0
rustc 1.38.0
rustc 1.39.0
rustc 1.4.0
rustc 1.40.0
rustc 1.41.0
rustc 1.42.0
rustc 1.43.0
rustc 1.44.0
rustc 1.45.0
rustc 1.45.2
rustc 1.46.0
rustc 1.47.0
rustc 1.48.0
rustc 1.49.0
rustc 1.5.0
rustc 1.50.0
rustc 1.51.0
rustc 1.52.0
rustc 1.53.0
rustc 1.54.0
rustc 1.55.0
rustc 1.56.0
rustc 1.57.0
rustc 1.58.0
rustc 1.59.0
rustc 1.6.0
rustc 1.60.0
rustc 1.61.0
rustc 1.62.0
rustc 1.63.0
rustc 1.64.0
rustc 1.65.0
rustc 1.66.0
rustc 1.67.0
rustc 1.68.0
rustc 1.69.0
rustc 1.7.0
rustc 1.70.0
rustc 1.71.0
rustc 1.72.0
rustc 1.73.0
rustc 1.74.0
rustc 1.75.0
rustc 1.76.0
rustc 1.77.0
rustc 1.78.0
rustc 1.79.0
rustc 1.8.0
rustc 1.80.0
rustc 1.81.0
rustc 1.82.0
rustc 1.83.0
rustc 1.84.0
rustc 1.85.0
rustc 1.86.0
rustc 1.87.0
rustc 1.88.0
rustc 1.89.0
rustc 1.9.0
rustc 1.90.0
rustc beta
rustc nightly
rustc-cg-gcc (master)
x86-64 GCCRS (GCC master)
x86-64 GCCRS (GCCRS master)
x86-64 GCCRS 14.1 (GCC assertions)
x86-64 GCCRS 14.1 (GCC)
x86-64 GCCRS 14.2 (GCC assertions)
x86-64 GCCRS 14.2 (GCC)
x86-64 GCCRS 14.3 (GCC assertions)
x86-64 GCCRS 14.3 (GCC)
x86-64 GCCRS 15.1 (GCC assertions)
x86-64 GCCRS 15.1 (GCC)
x86-64 GCCRS 15.2 (GCC assertions)
x86-64 GCCRS 15.2 (GCC)
Options
Source code
//! Efficient decimal integer formatting. //! //! # Safety //! //! This uses `CStr::from_bytes_with_nul_unchecked` and //! `str::from_utf8_unchecked`on the buffer that it filled itself. #![allow(unsafe_code)] use std::os::fd::{AsFd, AsRawFd}; use core::ffi::CStr; use core::any::TypeId; use core::mem::{self, MaybeUninit}; use itoa::{Buffer, Integer}; #[cfg(all(feature = "std", unix))] use std::os::unix::ffi::OsStrExt; #[cfg(all(feature = "std", target_os = "wasi"))] use std::os::wasi::ffi::OsStrExt; #[cfg(feature = "std")] use {core::fmt, std::ffi::OsStr, std::path::Path}; pub fn foo(i: i32) -> DecInt { DecInt::new(i) } /// Format an integer into a decimal `Path` component, without constructing a /// temporary `PathBuf` or `String`. /// /// This is used for opening paths such as `/proc/self/fd/<fd>` on Linux. /// /// # Examples /// /// ``` /// # #[cfg(any(feature = "fs", feature = "net"))] /// use rustix::path::DecInt; /// /// # #[cfg(any(feature = "fs", feature = "net"))] /// assert_eq!( /// format!("hello {}", DecInt::new(9876).as_ref().display()), /// "hello 9876" /// ); /// ``` #[derive(Clone)] pub struct DecInt { buf: [MaybeUninit<u8>; "-9223372036854775808\0".len()], len: usize, } impl DecInt { /// Construct a new path component from an integer. #[inline] pub fn new<Int: Integer + 'static>(i: Int) -> Self { let mut buf = [MaybeUninit::uninit(); 21]; let mut str_buf = Buffer::new(); let str_buf = str_buf.format(i); { assert!(str_buf.len() < buf.len(), "{str_buf}{} unsupported.", core::any::type_name::<Int>()); buf[..str_buf.len()].copy_from_slice(unsafe { // SAFETY: you can always go from init to uninit mem::transmute::<&[u8], &[MaybeUninit<u8>]>(str_buf.as_bytes()) }); buf[str_buf.len()] = MaybeUninit::new(0); } Self { buf, len: str_buf.len(), } } /// Construct a new path component from a file descriptor. #[inline] pub fn from_fd<Fd: AsFd>(fd: Fd) -> Self { Self::new(fd.as_fd().as_raw_fd()) } /// Return the raw byte buffer as a `&str`. #[inline] pub fn as_str(&self) -> &str { // SAFETY: `DecInt` always holds a formatted decimal number, so it's // always valid UTF-8. unsafe { core::str::from_utf8_unchecked(self.as_bytes()) } } /// Return the raw byte buffer as a `&CStr`. #[inline] pub fn as_c_str(&self) -> &CStr { let bytes_with_nul = self.as_bytes_with_nul(); debug_assert!(CStr::from_bytes_with_nul(bytes_with_nul).is_ok()); // SAFETY: `self.buf` holds a single decimal ASCII representation and // at least one extra NUL byte. unsafe { CStr::from_bytes_with_nul_unchecked(bytes_with_nul) } } /// Return the raw byte buffer including the NUL byte. #[inline] pub fn as_bytes_with_nul(&self) -> &[u8] { let init = &self.buf[..=self.len]; // SAFETY: we're guaranteed to have initialized len+1 bytes. unsafe { mem::transmute::<&[MaybeUninit<u8>], &[u8]>(init) } } /// Return the raw byte buffer. #[inline] pub fn as_bytes(&self) -> &[u8] { let bytes = self.as_bytes_with_nul(); &bytes[..bytes.len() - 1] } } mod itoa { //! [![github]](https://github.com/dtolnay/itoa) [![crates-io]](https://crates.io/crates/itoa) [![docs-rs]](https://docs.rs/itoa) //! //! [github]: https://img.shields.io/badge/github-8da0cb?style=for-the-badge&labelColor=555555&logo=github //! [crates-io]: https://img.shields.io/badge/crates.io-fc8d62?style=for-the-badge&labelColor=555555&logo=rust //! [docs-rs]: https://img.shields.io/badge/docs.rs-66c2a5?style=for-the-badge&labelColor=555555&logo=docs.rs //! //! <br> //! //! This crate provides a fast conversion of integer primitives to decimal //! strings. The implementation comes straight from [libcore] but avoids the //! performance penalty of going through [`core::fmt::Formatter`]. //! //! See also [`ryu`] for printing floating point primitives. //! //! [libcore]: https://github.com/rust-lang/rust/blob/b8214dc6c6fc20d0a660fb5700dca9ebf51ebe89/src/libcore/fmt/num.rs#L201-L254 //! [`core::fmt::Formatter`]: https://doc.rust-lang.org/std/fmt/struct.Formatter.html //! [`ryu`]: https://github.com/dtolnay/ryu //! //! # Example //! //! ``` //! fn main() { //! let mut buffer = itoa::Buffer::new(); //! let printed = buffer.format(128u64); //! assert_eq!(printed, "128"); //! } //! ``` //! //! # Performance (lower is better) //! //! 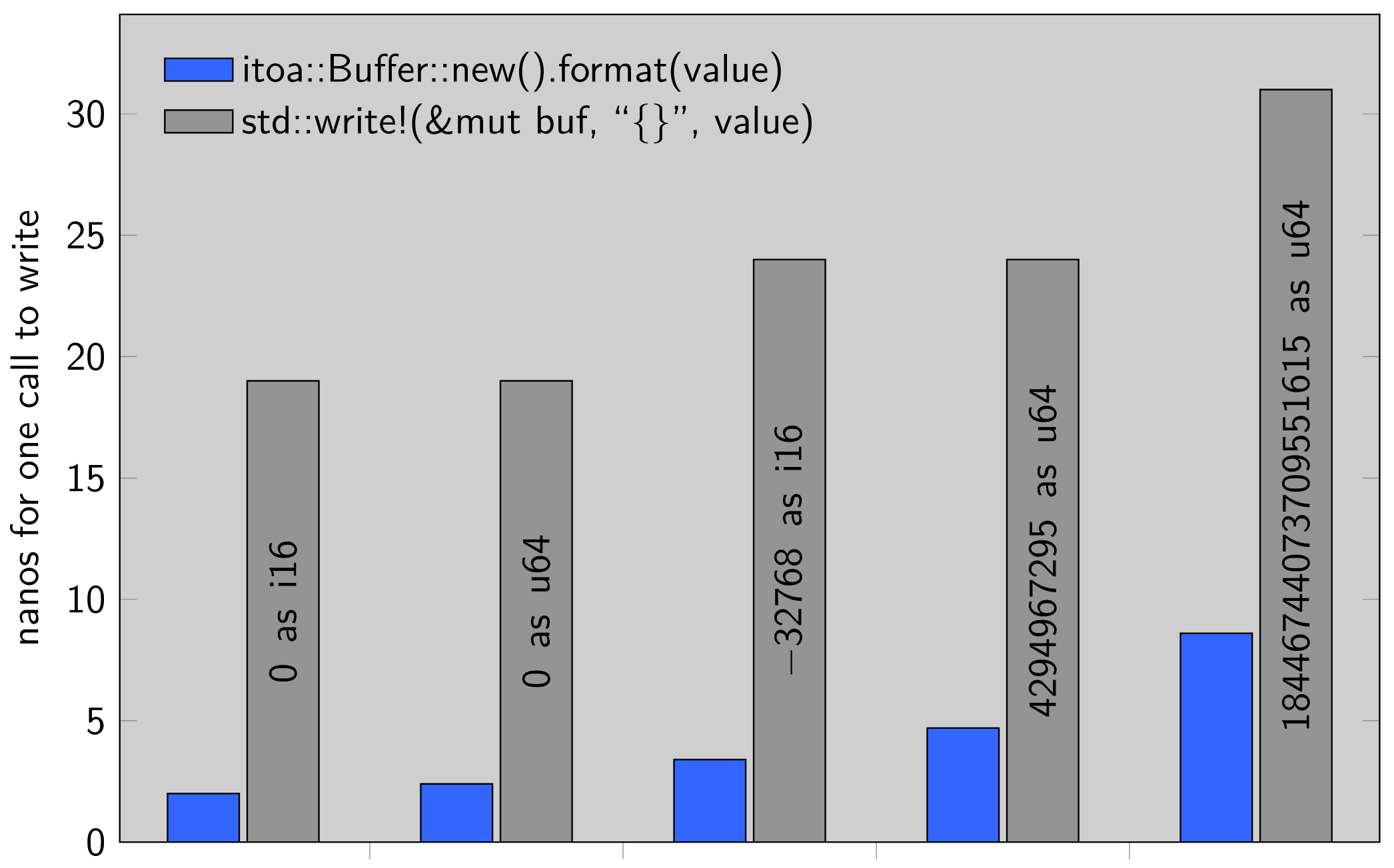 // #![doc(html_root_url = "https://docs.rs/itoa/1.0.11")] #![no_std] #![allow( clippy::cast_lossless, clippy::cast_possible_truncation, clippy::cast_possible_wrap, clippy::cast_sign_loss, clippy::expl_impl_clone_on_copy, clippy::must_use_candidate, clippy::needless_doctest_main, clippy::unreadable_literal )] use core::mem::{self, MaybeUninit}; use core::{ptr, slice, str}; #[cfg(feature = "no-panic")] use no_panic::no_panic; /// A correctly sized stack allocation for the formatted integer to be written /// into. /// /// # Example /// /// ``` /// let mut buffer = itoa::Buffer::new(); /// let printed = buffer.format(1234); /// assert_eq!(printed, "1234"); /// ``` pub struct Buffer { bytes: [MaybeUninit<u8>; I128_MAX_LEN], } impl Default for Buffer { #[inline] fn default() -> Buffer { Buffer::new() } } impl Copy for Buffer {} impl Clone for Buffer { #[inline] #[allow(clippy::non_canonical_clone_impl)] // false positive https://github.com/rust-lang/rust-clippy/issues/11072 fn clone(&self) -> Self { Buffer::new() } } impl Buffer { /// This is a cheap operation; you don't need to worry about reusing buffers /// for efficiency. #[inline] #[cfg_attr(feature = "no-panic", no_panic)] pub fn new() -> Buffer { let bytes = [MaybeUninit::<u8>::uninit(); I128_MAX_LEN]; Buffer { bytes } } /// Print an integer into this buffer and return a reference to its string /// representation within the buffer. #[cfg_attr(feature = "no-panic", no_panic)] pub fn format<I: Integer>(&mut self, i: I) -> &str { let str = i.write(unsafe { &mut *(&mut self.bytes as *mut [MaybeUninit<u8>; I128_MAX_LEN] as *mut <I as private::Sealed>::Buffer) }); if str.len() > I::MAX_STR_LEN { unsafe { core::hint::unreachable_unchecked() } } str } } /// An integer that can be written into an [`itoa::Buffer`][Buffer]. /// /// This trait is sealed and cannot be implemented for types outside of itoa. pub trait Integer: private::Sealed { /// The maximum length of the formated str for this integer. const MAX_STR_LEN: usize; } // Seal to prevent downstream implementations of the Integer trait. mod private { pub trait Sealed: Copy { type Buffer: 'static; fn write(self, buf: &mut Self::Buffer) -> &str; } } const DEC_DIGITS_LUT: &[u8] = b"\ 0001020304050607080910111213141516171819\ 2021222324252627282930313233343536373839\ 4041424344454647484950515253545556575859\ 6061626364656667686970717273747576777879\ 8081828384858687888990919293949596979899"; // Adaptation of the original implementation at // https://github.com/rust-lang/rust/blob/b8214dc6c6fc20d0a660fb5700dca9ebf51ebe89/src/libcore/fmt/num.rs#L188-L266 macro_rules! impl_Integer { ($($max_len:expr => $t:ident),* as $conv_fn:ident) => {$( impl Integer for $t { const MAX_STR_LEN: usize = $max_len; } impl private::Sealed for $t { type Buffer = [MaybeUninit<u8>; $max_len]; #[allow(unused_comparisons)] #[inline] #[cfg_attr(feature = "no-panic", no_panic)] fn write(self, buf: &mut [MaybeUninit<u8>; $max_len]) -> &str { let is_nonnegative = self >= 0; let mut n = if is_nonnegative { self as $conv_fn } else { // Convert negative number to positive by summing 1 to its two's complement. (!(self as $conv_fn)).wrapping_add(1) }; let mut curr = buf.len() as isize; let buf_ptr = buf.as_mut_ptr() as *mut u8; let lut_ptr = DEC_DIGITS_LUT.as_ptr(); // Need at least 16 bits for the 4-digits-at-a-time to work. if mem::size_of::<$t>() >= 2 { // Eagerly decode 4 digits at a time. while n >= 10000 { let rem = (n % 10000) as isize; n /= 10000; let d1 = (rem / 100) << 1; let d2 = (rem % 100) << 1; curr -= 4; unsafe { ptr::copy_nonoverlapping(lut_ptr.offset(d1), buf_ptr.offset(curr), 2); ptr::copy_nonoverlapping(lut_ptr.offset(d2), buf_ptr.offset(curr + 2), 2); } } } // If we reach here, numbers are <=9999 so at most 4 digits long. let mut n = n as isize; // Possibly reduce 64-bit math. // Decode 2 more digits, if >2 digits. if n >= 100 { let d1 = (n % 100) << 1; n /= 100; curr -= 2; unsafe { ptr::copy_nonoverlapping(lut_ptr.offset(d1), buf_ptr.offset(curr), 2); } } // Decode last 1 or 2 digits. if n < 10 { curr -= 1; unsafe { *buf_ptr.offset(curr) = (n as u8) + b'0'; } } else { let d1 = n << 1; curr -= 2; unsafe { ptr::copy_nonoverlapping(lut_ptr.offset(d1), buf_ptr.offset(curr), 2); } } if !is_nonnegative { curr -= 1; unsafe { *buf_ptr.offset(curr) = b'-'; } } let len = buf.len() - curr as usize; let bytes = unsafe { slice::from_raw_parts(buf_ptr.offset(curr), len) }; unsafe { str::from_utf8_unchecked(bytes) } } } )*}; } const I8_MAX_LEN: usize = 4; const U8_MAX_LEN: usize = 3; const I16_MAX_LEN: usize = 6; const U16_MAX_LEN: usize = 5; const I32_MAX_LEN: usize = 11; const U32_MAX_LEN: usize = 10; const I64_MAX_LEN: usize = 20; const U64_MAX_LEN: usize = 20; impl_Integer!( I8_MAX_LEN => i8, U8_MAX_LEN => u8, I16_MAX_LEN => i16, U16_MAX_LEN => u16, I32_MAX_LEN => i32, U32_MAX_LEN => u32 as u32); impl_Integer!(I64_MAX_LEN => i64, U64_MAX_LEN => u64 as u64); #[cfg(target_pointer_width = "16")] impl_Integer!(I16_MAX_LEN => isize, U16_MAX_LEN => usize as u16); #[cfg(target_pointer_width = "32")] impl_Integer!(I32_MAX_LEN => isize, U32_MAX_LEN => usize as u32); #[cfg(target_pointer_width = "64")] impl_Integer!(I64_MAX_LEN => isize, U64_MAX_LEN => usize as u64); macro_rules! impl_Integer128 { ($($max_len:expr => $t:ident),*) => {$( impl Integer for $t { const MAX_STR_LEN: usize = $max_len; } impl private::Sealed for $t { type Buffer = [MaybeUninit<u8>; $max_len]; #[allow(unused_comparisons)] #[inline] #[cfg_attr(feature = "no-panic", no_panic)] fn write(self, buf: &mut [MaybeUninit<u8>; $max_len]) -> &str { let is_nonnegative = self >= 0; let n = if is_nonnegative { self as u128 } else { // Convert negative number to positive by summing 1 to its two's complement. (!(self as u128)).wrapping_add(1) }; let mut curr = buf.len() as isize; let buf_ptr = buf.as_mut_ptr() as *mut u8; // Divide by 10^19 which is the highest power less than 2^64. let (n, rem) = udiv128::udivmod_1e19(n); let buf1 = unsafe { buf_ptr.offset(curr - U64_MAX_LEN as isize) as *mut [MaybeUninit<u8>; U64_MAX_LEN] }; curr -= rem.write(unsafe { &mut *buf1 }).len() as isize; if n != 0 { // Memset the base10 leading zeros of rem. let target = buf.len() as isize - 19; unsafe { ptr::write_bytes(buf_ptr.offset(target), b'0', (curr - target) as usize); } curr = target; // Divide by 10^19 again. let (n, rem) = udiv128::udivmod_1e19(n); let buf2 = unsafe { buf_ptr.offset(curr - U64_MAX_LEN as isize) as *mut [MaybeUninit<u8>; U64_MAX_LEN] }; curr -= rem.write(unsafe { &mut *buf2 }).len() as isize; if n != 0 { // Memset the leading zeros. let target = buf.len() as isize - 38; unsafe { ptr::write_bytes(buf_ptr.offset(target), b'0', (curr - target) as usize); } curr = target; // There is at most one digit left // because u128::MAX / 10^19 / 10^19 is 3. curr -= 1; unsafe { *buf_ptr.offset(curr) = (n as u8) + b'0'; } } } if !is_nonnegative { curr -= 1; unsafe { *buf_ptr.offset(curr) = b'-'; } } let len = buf.len() - curr as usize; let bytes = unsafe { slice::from_raw_parts(buf_ptr.offset(curr), len) }; unsafe { str::from_utf8_unchecked(bytes) } } } )*}; } const U128_MAX_LEN: usize = 39; const I128_MAX_LEN: usize = 40; impl_Integer128!(I128_MAX_LEN => i128, U128_MAX_LEN => u128); mod udiv128 { #[cfg(feature = "no-panic")] use no_panic::no_panic; /// Multiply unsigned 128 bit integers, return upper 128 bits of the result #[inline] #[cfg_attr(feature = "no-panic", no_panic)] fn u128_mulhi(x: u128, y: u128) -> u128 { let x_lo = x as u64; let x_hi = (x >> 64) as u64; let y_lo = y as u64; let y_hi = (y >> 64) as u64; // handle possibility of overflow let carry = (x_lo as u128 * y_lo as u128) >> 64; let m = x_lo as u128 * y_hi as u128 + carry; let high1 = m >> 64; let m_lo = m as u64; let high2 = (x_hi as u128 * y_lo as u128 + m_lo as u128) >> 64; x_hi as u128 * y_hi as u128 + high1 + high2 } /// Divide `n` by 1e19 and return quotient and remainder /// /// Integer division algorithm is based on the following paper: /// /// T. Granlund and P. Montgomery, “Division by Invariant Integers Using Multiplication” /// in Proc. of the SIGPLAN94 Conference on Programming Language Design and /// Implementation, 1994, pp. 61–72 /// #[inline] #[cfg_attr(feature = "no-panic", no_panic)] pub fn udivmod_1e19(n: u128) -> (u128, u64) { let d = 10_000_000_000_000_000_000_u64; // 10^19 let quot = if n < 1 << 83 { ((n >> 19) as u64 / (d >> 19)) as u128 } else { u128_mulhi(n, 156927543384667019095894735580191660403) >> 62 }; let rem = (n - quot * d as u128) as u64; debug_assert_eq!(quot, n / d as u128); debug_assert_eq!(rem as u128, n % d as u128); (quot, rem) } } }
Become a Patron
Sponsor on GitHub
Donate via PayPal
Compiler Explorer Shop
Source on GitHub
Mailing list
Installed libraries
Wiki
Report an issue
How it works
Contact the author
CE on Mastodon
CE on Bluesky
Statistics
Changelog
Version tree